ChatGPTの登場により注目を浴びた生成AIですが、今ではいたるところで日常的に利用されるようになりました。さらに、高性能な生成AIモデルの登場で、既存モデルが安価で提供されるようになったり、生成AIモデルの既知の欠点が新技術で補われたりと、生成AI活用おける課題が次々と解消されています。AIブームの勢いは落ち着いてきてはいるものの、生成AI関連のサービスが提供し易くなることで、これからも普及していくのではないでしょうか。そこで当記事では、生成AIであるLLM(Large Language Model:大規模言語モデル)の欠点を補う技術のひとつ、RAGにスポットを当てたいと思います。RAGはLLMを語るうえで切り離せないトレンド技術であり、RAGを用いてモデルの品質を向上させたサービスが次々と登場しています。
当記事では、これからRAGに触れる技術者の方、LLMの精度向上のためにRAGを検討している方などを対象とした導入レベルの内容を少しだけ詳しく説明していきたいと思います。


RAGとは
RAG(Retrieval-Augmented Generation:検索拡張生成)とは、入力内容をそのままLLMに与えずに、まずは入力内容に関係する情報を外部から収集し、収集した情報と入力内容をLLMに与えることで回答精度を上げる技術のことです。
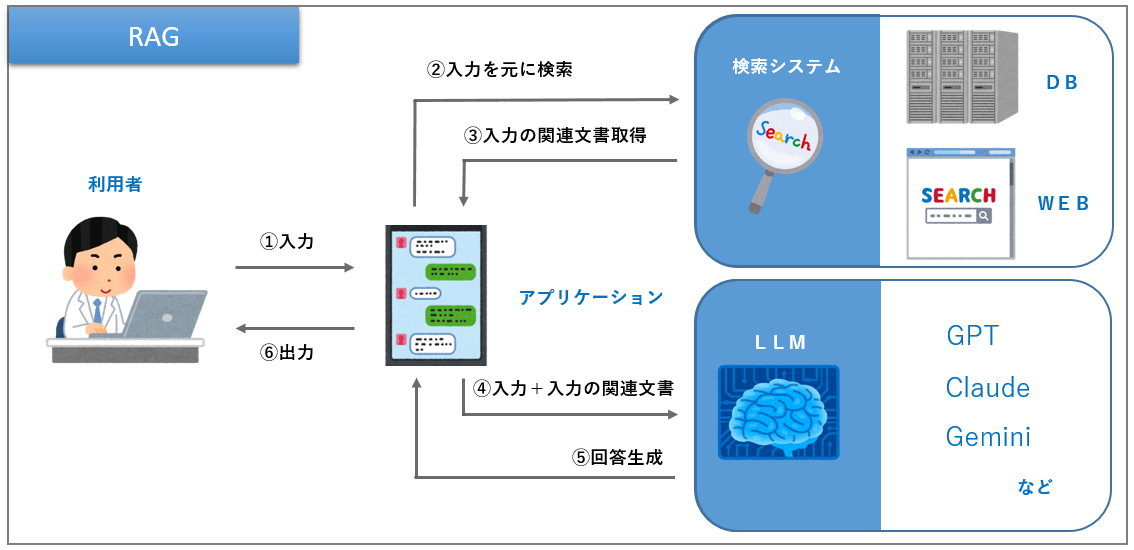
RAGを用いることでLLMの以下の欠点を補うことができます。
- 学習していないことについては回答できない。(最新情報、社内情報など)
- 事実と異なる回答をしてしまう。(ハルシネーション)
それでは何故、RAGを使うことでこれらの欠点を補うことができるのかを説明します。
LLMへの入力をプロンプトと呼びますが、LLMはそのプロンプトから一時的に学習する機能(コンテキスト内学習)という能力を持っています。下図はgpt-3.5-turboに対して、コンテキスト内学習の有無でどのように回答が変化するのかを検証したときの結果をイメージ化したものです。この例では、コンテキスト内学習の箇所にシステムプロンプトと呼ばれる通常より少し強力なプロンプトを使用しています。
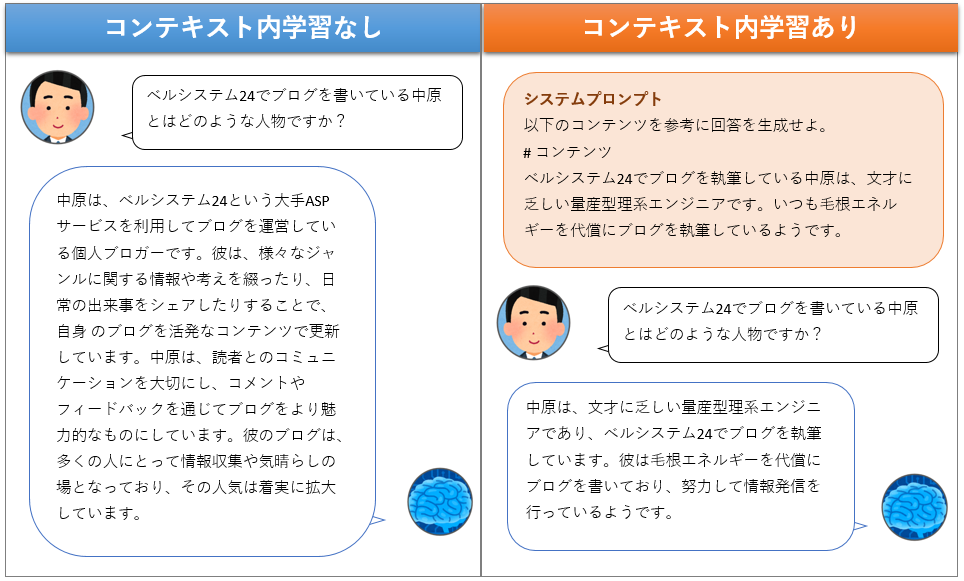
コンテキスト内学習なしの場合、「ブログを書いている」という情報から話を膨らませたのか、さらりと人気の個人ブロガーに祭り上げられてしまいました。もちろん事実と異なるので、AIが誤った情報を生成してしまう現象(ハルシネーション)が発生している状態と言えます。
そしてコンテキスト内学習ありの場合、LLMに事前に与えた情報が回答に反映され、ハルシネーションを防ぐことができました。
RAGでは、この技術を冒頭の図の④(入力+入力の関連文書)の箇所で利用します。検索結果(入力内容に適した情報)を使いコンテキスト内学習をしてから回答することで、前述の例と同様の効果を得ることができます。
これがモデルの欠点を補い、モデルの精度向上を実現するRAGのメカニズムになります。
さて、ここまでは検索システムについて細かな説明を省略していましたが、実はRAGの主要機能は検索(Retrieval)です。モデルの精度向上を実現するプロンプトを作るためには、有用な情報を取得する必要があります。では、どこからどのように取得すればよいのでしょうか。
次セクションからは検索の仕組みについて、検索対象別に深堀りして解説します。


インターネット検索
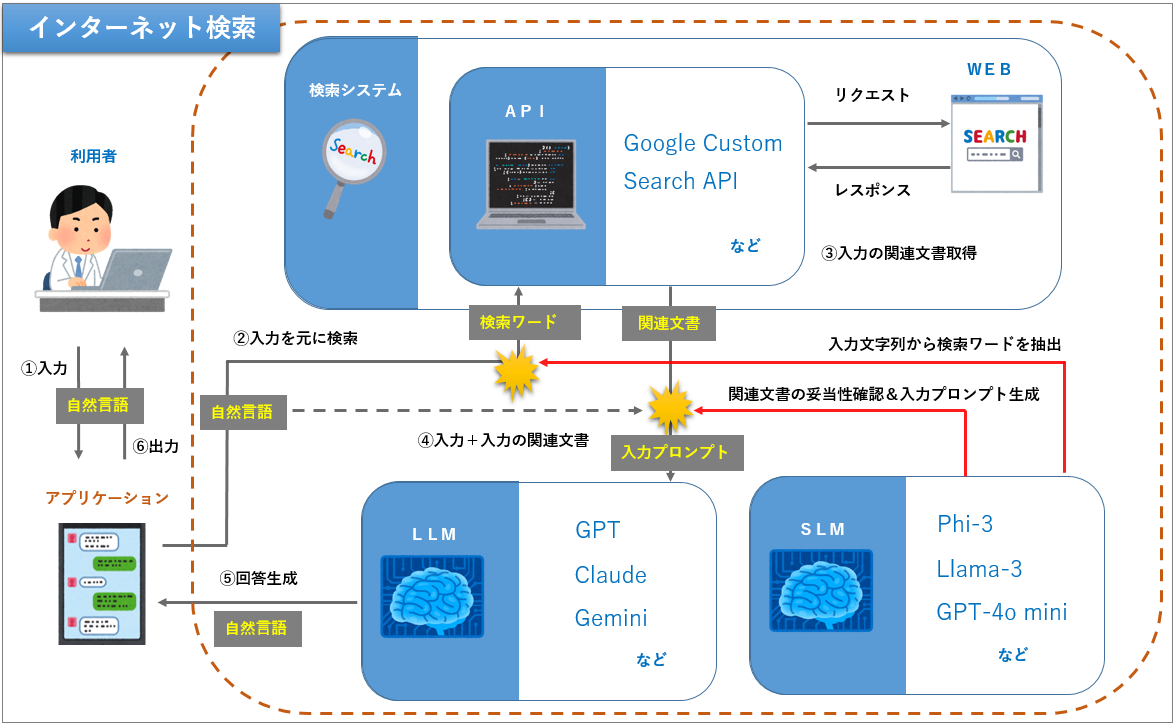
検索エンジンを利用したい場合などに検討する構成です。スクレイピングやクローリングと呼ばれる、対象のWEBサイトのHTMLを解析して情報を取得する従来の技術もありますが、これを行うと対象のサイトに大きな負荷かけてしまうため利用規約で禁止されているケースも少なくありません。なので、特別な理由が無い限りインターネット検索を実装する場合はAPIを利用した方が安全です。例えば、Googleも規約ではこれらを禁止とし、API(Google Custom Search API)を提供しています。リンク先に様々な実装例が記載されていますが、LangChainを使うと下記のようなシンプルなコードで実装可能です。
※APIを利用するにはGCP(Google Cloud Platform)へログイン後、APIキー(GOOGLE_API_KEY)と検索エンジンID(GOOGLE_CSE_ID)を入手する必要があります。
import os
from langchain_google_community import GoogleSearchAPIWrapper
os.environ["GOOGLE_API_KEY"] = ""
os.environ["GOOGLE_CSE_ID"] = ""
google_search = GoogleSearchAPIWrapper()
response = google_search.run("検索ワード")
RAGでインターネット検索がしたい場合、入力が自然言語ですので入力文字列から検索ワードを抽出し、WEB検索を実施した方が意図した情報を取得しやすいです。また、WEB検索の結果は期待外れの情報が得られることも多いため、検索結果をLLMに与える前に入力文字列と関連のある情報を取得できているかをチェックするプロセスを挟むと精度UPが期待できます。いずれもLLMを使って実現可能ですが、特定の分野に特化した軽量のSLM(Small Language Models:小規模言語モデル)でも実現可能なので、うまく活用するとコスト削減が見込めます。近年ではこのSLMが注目されており、特定分野においてはLLMをも超えるものまであるそうです。
さて、下図はインターネット検索を実装したRAGアプリケーションの構成例です。このセクションの内容を再確認してみてください。
DB検索(SQL)
全てのデータベースの中で、RDB(Relational DataBase:リレーショナルデータベース)は今でも圧倒的なシェアを誇っています。なので、世の中の多くのデータはこのタイプのデータソースに格納されていると言えます。そして、これらのデータへアクセスする際にはSQLを使います。RDBやSQLは広く知られているため、細かな説明は割愛します。
RAGでDB検索がしたい場合、入力の自然言語からSQLを生成したあとにRDBの情報を取得することになります。こちらもLLMなどを用いてSQLを生成することはできますが、複雑であるほど難易度は上がります。
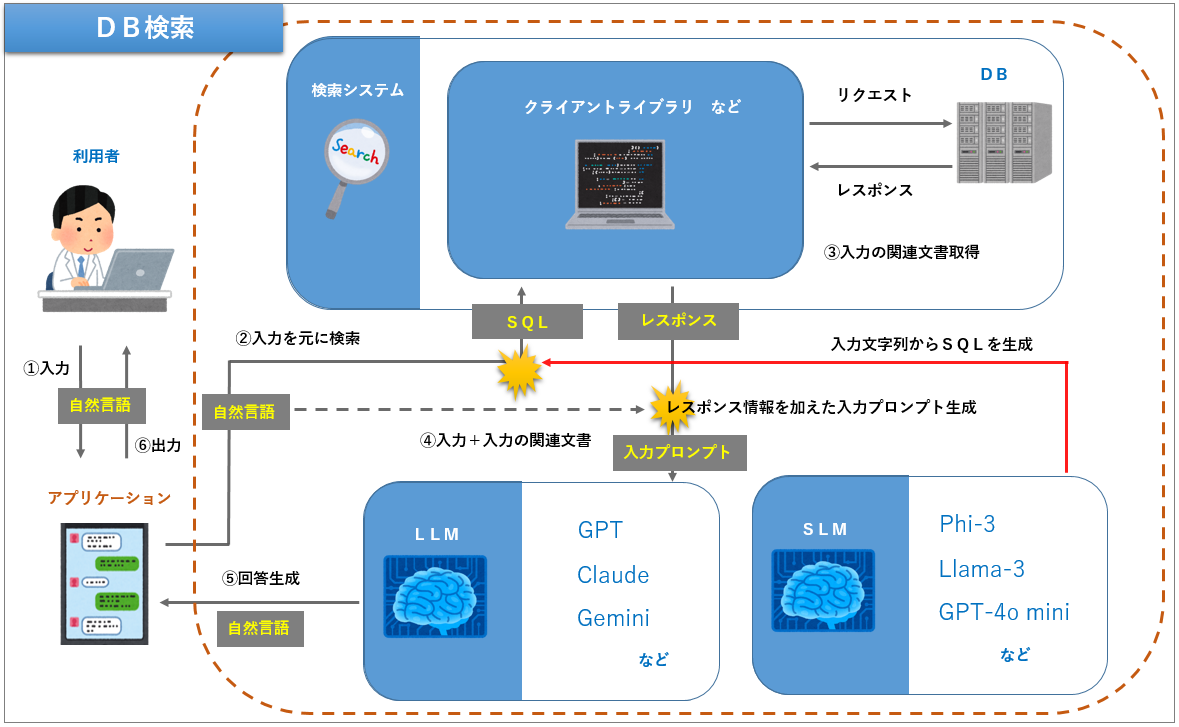
また、RDBに限らず、SQLを用いて対話可能なデータソースを検索する場合はすべてこちらの構成を採用することができます。この構成を採用すると、例えば、他では使わないようなローカル用語の辞書テーブルをお持ちの場合、DB検索で用語チェックを実施してからLLMに回答させることでローカルな用語を含む質問にも対応できるようになりますし、商品情報関連のテーブルをお持ちの場合、金額や在庫状況などを把握した状態で回答することができるようになります。
ベクトルDB検索
ベクトルを検索して何が嬉しいかを理解するために、まずはベクトルについて簡単に説明します。
機械学習では学習対象の特徴だけを学習することが多いのですが、その抽出された特徴のことを特徴ベクトル(feature vector)と呼びます。ベクトルとは向きと大きさを持つもので、これは特徴を定量的な数値表現したものになります。例えば、リンゴは赤いですよね。その「赤」を0~1の数値で表して、0.9としたとします。これは、リンゴから「赤」という向きに0.9という大きさの特徴ベクトルを1つ抽出したことになります。また、リンゴは丸いですよね。その「丸い」を0~1の数値で表して、0.8としましょう。これで、リンゴから特徴ベクトルを2つ抽出したことになります。ただ2つの特徴を数値化しただけですが、これを、2次元の特徴ベクトルなんて表現したりします。
それでは次に、トマトの場合を考えてみましょう。同様に「赤」と「丸い」を数値化したとき、いずれもリンゴに近い数値になるのではないでしょうか。これは、リンゴとトマトを赤さで比較しても、丸さで比較しても似ているためです。このような2次元のベクトルは下図のように2次元の座標系で表現することができ、リンゴとトマトはそれぞれ近い位置にプロットされます。そして、距離が近いということは似ていることを意味します。具体的な距離の計算方法はいくつかありますが、最も一般的な方法はユークリッド距離を使った計算です。
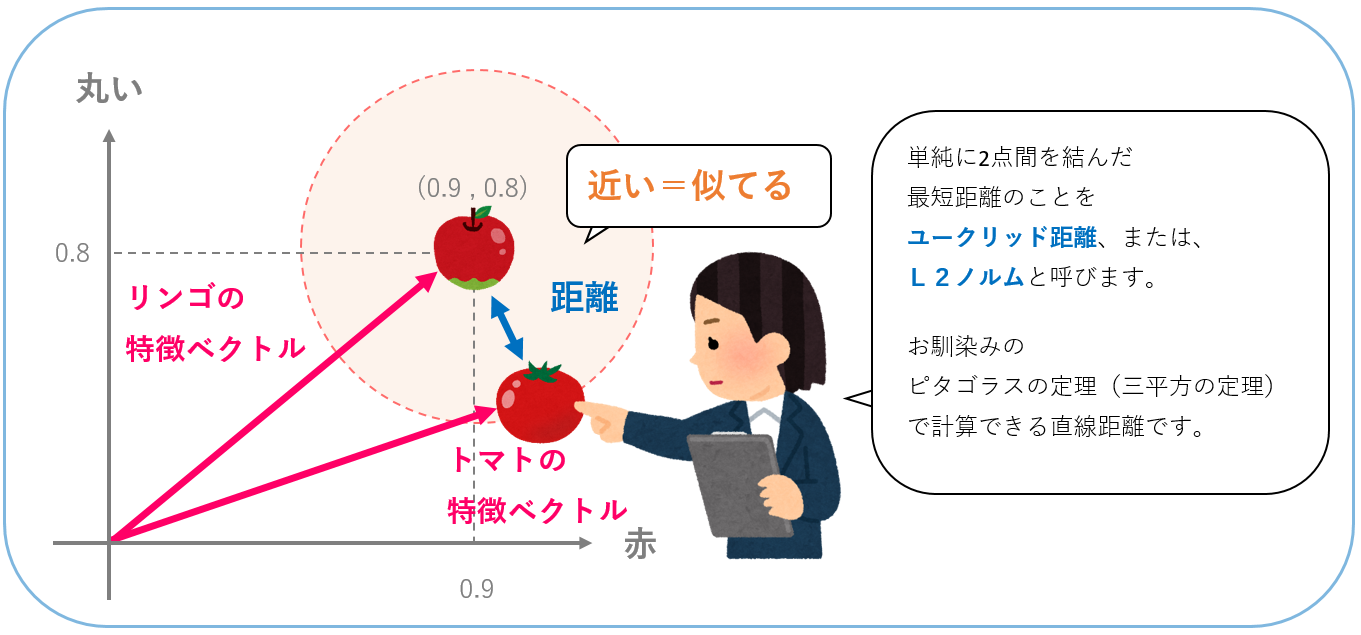
つまり、ベクトル同士の距離を比較することで、特徴が似ているものを見つけることが出来ます。これがベクトル検索の基本的なメカニズムです。
ちなみに、「2次元ユークリッド空間にデータを埋め込む(Enbedding)」という表現もよく使われますが、先ほどの例と同じく、データから2種類の特徴を数値化して2次元座標にプロットすることを指します。また、先ほどはリンゴから2つの特徴を抽出しましたが、他にも特徴があると思います。つまり、リンゴは2次元以上(高次元)の情報を持っていると言えます。そこから意味を保ったまま低次元の情報に落とし込むことを次元削減と呼びます。いずれも特徴量の抽出を意味する表現になります。
素直にベクトル検索をする場合、機械学習アルゴリズムのk近傍法(kNN:k-Nearest Neighbor)を使えば、全ベクトルとの距離を計算・比較してくれるので、簡単に対象と類似したk個のベクトルを取得可能です。
ですが、全てのベクトルとの距離を計算するには、データ量や次元数が増えるほど、処理時間は増加し、ハイスペックな動作環境が必要となるため、システムのスケーリングが難しくなります。
そこで活躍するのがベクトルDBです。ベクトルDBは、近似最近傍探索(ANN)タイプのアルゴリズム(HNSW、IVF、PQなど)を用いたインデックスでベクトルを管理しており、ベクトル検索の高速化を実現しています。ただし、精度と速度はトレードオフの関係にあり、ANNは近似計算なので、k近傍法に比べると精度は低くなります。もし、コストをかけてでも精度を落としたくない場合は、kNNタイプのインデックスに対応しているDBもあるので検討するのも良いでしょう.
最後に、自然言語のベクトル化について少しだけ説明します。
自然言語をベクトル化する手法は大きく分けて、Bag of Words(BoW)と分散表現の2種類あります。Bag of Wordsは、文中にある単語の出現数をもとにベクトル化する手法で、TF-IDFが代表的なアルゴリズムです。非常にシンプルなのですが、「猫」と「ネコ」のような表記のゆらぎなどには弱いので事前に正規化するなどの対応が必要です。分散表現と呼ばれる手法は、単語の意味や文法をもとにベクトル化する手法で、word2vecが代表的なアルゴリズムです。表記のゆらぎには強いですが、「私はあなたが好きです」と「私はあなたが嫌いです」などの対義語に弱い傾向にあります。いずれの方法も、精度向上の技術が次々と発見され、進化し続けています。
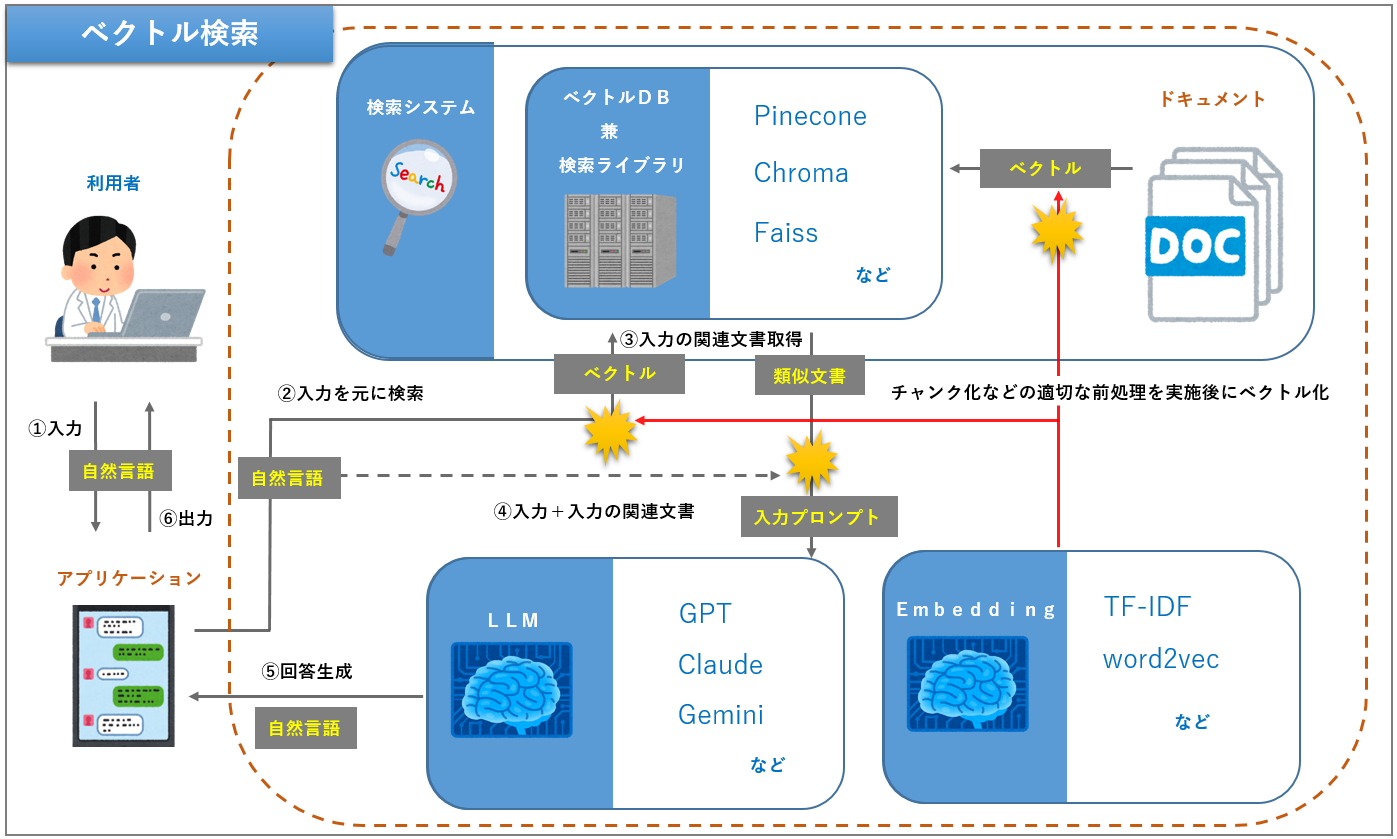
RAGアプリケーションの構成は次のようになりますが、入力文字列とドキュメントのベクトル化手法は同一のものでないと正しく比較できないので注意が必要です。ベクトル検索の強みは、類似性を検索できることにあります。
グラフDB検索
ここで取り扱うグラフとは、折れ線グラフや棒グラフのようなものではなく、数学のグラフ理論で定義されているグラフ(点と辺で構成された図形)のことを指します。グラフ理論は、複雑な繋がりでもシンプルな表現で視覚化できるため、多くの分野で活用されています。
グラフRAGでは、この理論を応用したナレッジグラフというものを一般的に使用します。ナレッジグラフが選ばれる理由は、柔軟性が高く、幅広い表現能力があるからです。しかし、ナレッジグラフとは何かといえば、明確な定義がなく、専門家でも意見が割れているため言い切るのは難しいです。それぞれの主張に共通している内容をピックアップして説明するなら、意味のある知識(ナレッジ)の表現と利用を可能にする構造を持っているグラフということになります。作成方法もいくつかありますが、ここでは、代表的なナレッジグラフのモデリング手法を2つだけ紹介したいと思います。
■RDF(Resource Description Framework)モデル
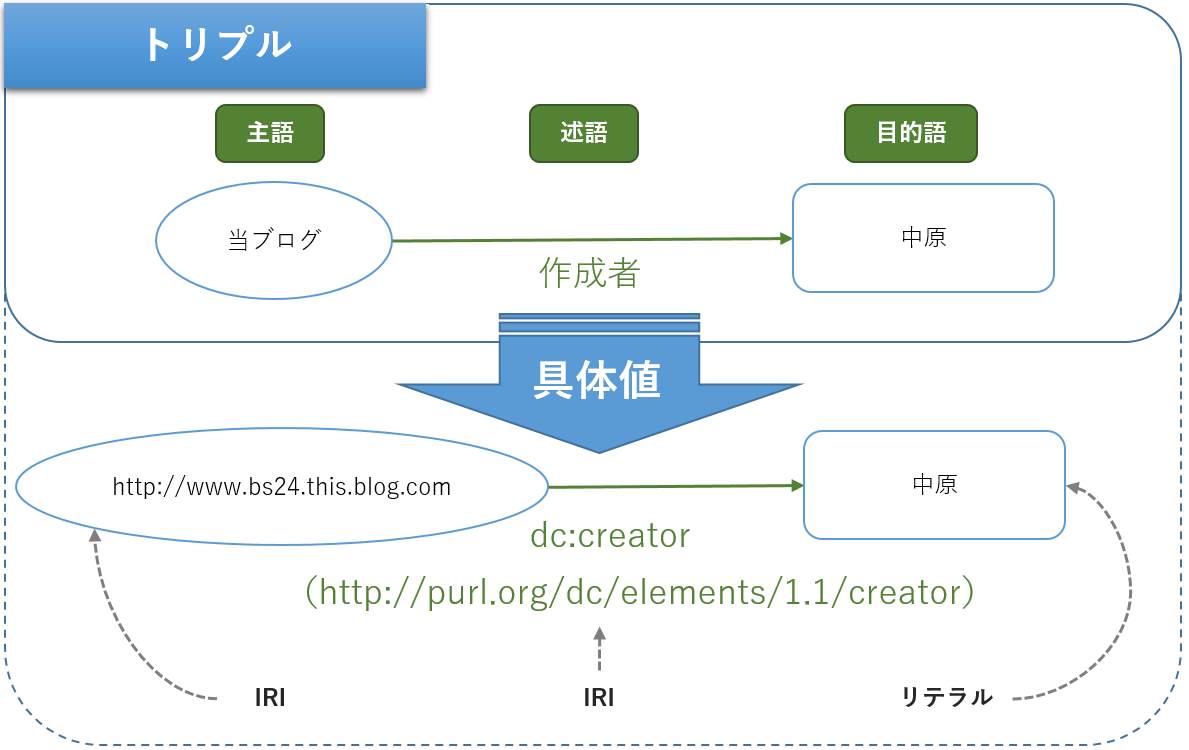
インターネットはPCなどの情報端末同士のつながりのことを指し、WWW(World Wide Web)は、インターネット上に公開されたWEBページ同士のつながりのことを指します。この、人が読むためのWEBに対して、W3C(World Wide Web Consortium)は、セマンティックWEB(WEBページの個々の情報に意味を付け加え、機械が情報を処理しやすくする技術)という概念を提唱しました。しかし、既存の技術だけでこれを実現させるのは難しいため、RDFというメタデータ(データに関するデータ)を定義する言語が作られました。RDFはセマンティックウェブにおけるデータ定義の最小構成であり、下図のようなトリプルと言う3要素(主語、述語、目的語)からなる有方グラフ構造になっています。主語と述語にはIRI(Internationalized Resource Identifier)という国際化されたURIを指定し、目的語にはIRI、または、リテラル(数値や文字列)を指定するという仕様になっています。
これをRDFで表現すると、下記のようになります。RDFの記法は、かなりバリエーションがありますが、この例ではDublin Coreを用いたXMLで作成しました。リンク先に使用可能な修飾子などが記載されているので興味のある方は確認してみてください。
<?xml version="1.0" encoding="Shift_JIS" ?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xml:lang="ja">
<rdf:Description rdf:about="http://www.bs24.this.blog.com">
<dc:creator>中原</dc:creator>
</rdf:Description>
</rdf:RDF>
トリプル同士の基本的な関係性だけであればRDFのみで十分表現できますが、複雑な関係性を表現したい場合はOWL(Web Ontology Language)などのオントロジー言語の使用を推奨します。オントロジーとは、特定の分野における概念やそれらの関係性を体系的に表現したもので、オントロジー言語を使うとデータをその分野に適した構造に標準化することができます。また、標準化することで、オントロジー言語準拠のデータ同士の共有が容易になります。W3Cは、セマンティックWEBの実現に向けてLinked Dataという、データを構造化し、互いにリンクさせるための原則を定義しました。この原則を満たしてオープンデータ化したものをLOD(Linked Open Data)と呼び、LODによって形成されたネットワークこそがセマンティックWEBの概念から発展した現在の姿です。そしてこれをナレッジグラフと呼ぶこともあります。LODは、WikidataやDBpediaなど、既に多く存在しており、基本的にSPARQLを用いてアクセス可能です。(原則に明記されているものの、SPARQLが使えないLODもあるようです)
■PG(Property Graph)モデル
プロパティグラフはインターネット情報向けのモデルではなく、汎用的なグラフデータのモデルであり、ノード(点)、リレーションシップ(辺)、プロパティの3要素を含むことが必要最低限の構成となります。グラフDBで取り扱うのは主にこちらのタイプで、このプロパティグラフで構成されたネットワークが、ここで言うナレッジグラフとなります。
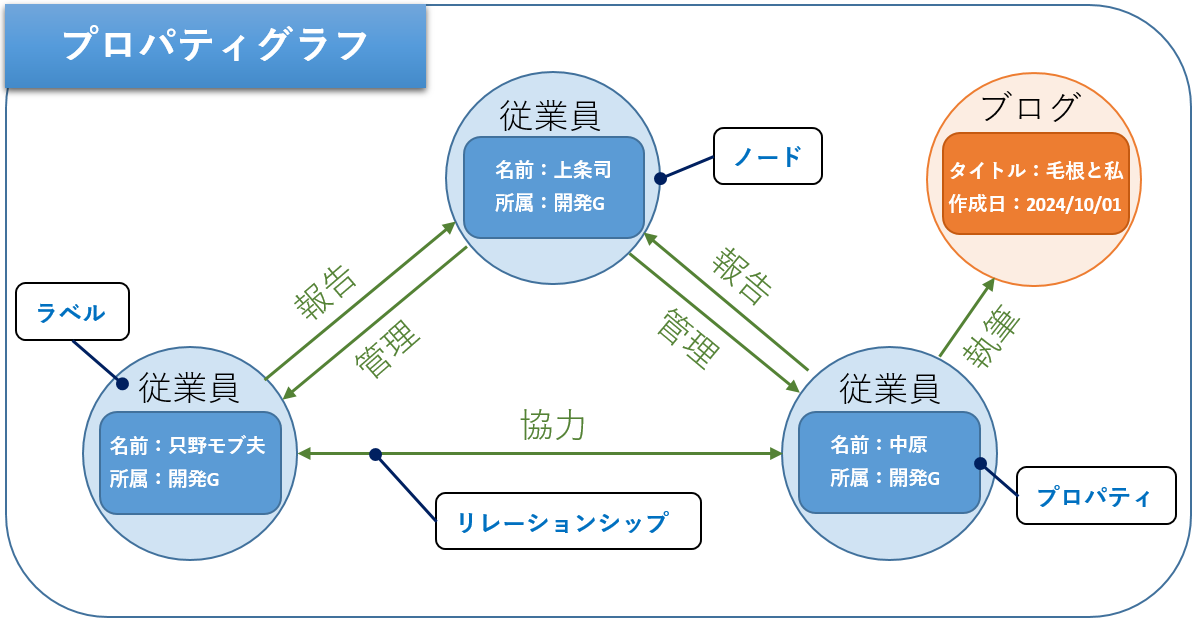
グラフDBの市場規模は拡大しており、グラフを扱えるDBが増えてきています。グラフDBには、もとからグラフ用に作られたネイティブなグラフDBと、元々グラフを扱えなかったDBにあとからグラフDB機能が追加された非ネイティブなグラフDBの2パターンあります。それぞれ以下のようなメリットとデメリットがあるので把握しておくとよいでしょう。
【ネイティブなグラフDB】
メリット
- グラフ処理に最適化されているため、複雑な関係性の検索/分析が高速
- グラフ構造に特化したクエリ言語を搭載
- グラフ可視化ツールを搭載
デメリット
- 特有のモデリングやクエリを扱うため、技術者の学習コストがかかる
- グラフ以外の処理に適していないこともある
- 導入や運用のコストが高い
【非ネイティブなグラフDB】
メリット
- 複数のデータモデルを扱える(グラフ、構造化されたデータ、Key/Valueなど)
- グラフ用DBを個別に立てる必要がなくなるのでコスト削減可能
- 既存の技術が使いまわせる可能性がある(学習コストを抑えられる)
デメリット
- ネイティブなグラフDBより複雑な関係性の処理が遅い
- グラフ特化のクエリ言語がなかったり制限があったりする
- 直感的に見やすいレベルの可視化ができない
また、グラフDBに対応したクエリ言語についても多く存在し、統一されていないのですが、GremlinとCypherが特に有名なので簡単に説明します。Gremlinは、Apache TinkerPop フレームワークの一部として開発されたトラバーサル言語でグラフ構造の要素を横断的に探索・処理することが得意です。多くのグラフデータベースでサポートされており、ポータビリティが高いです。Cypherは、Neo4jが開発したグラフクエリ言語で、SQLに似た構文を持つため、SQLに馴染みのある人にとっては学習しやすいです。グラフのCRUD操作(Create、Read、Update、Delete)をサポートし、複雑なパターンマッチングが得意です。
ちなみに、Neo4jというグラフDBは、ネイティブなグラフDBの中でも圧倒的なシェアを誇っています。また、Neo4jに対応するクエリ言語であるCypherはopenCypherという形でOSS化しており、共通クエリ言語化を目指しているようです。
最後に、自然言語のグラフ化について少しだけ説明します。
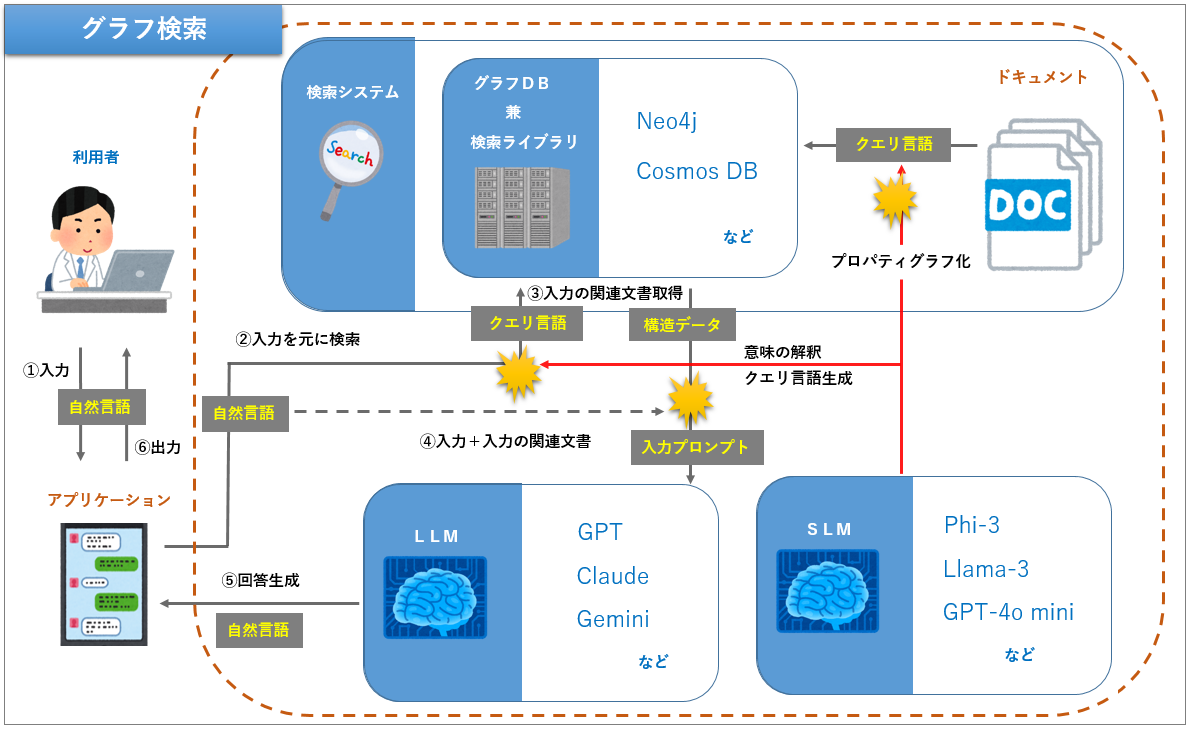
グラフDBで自然言語を扱う場合、ベクトルのように文章の塊で扱うのではなく、文章の意味を解釈しながらプロパティグラフ(ノードやリレーション、その他の情報)へ変換します。また、グラフ検索する際は入力の自然言語の意味を理解し、どのようなクエリが必要かを判断してクエリ言語に変換する必要があるため、少々複雑になります。SLMで上手くいかない場合はLLMの使用も選択肢に入ります。そのため、RAGでグラフDBを検索する場合は以下の構成になります。
まとめ
最後までお付き合いいただき、ありがとうございます。当記事で紹介したRAGはいずれも説明のために比較的シンプルな構成のものをピックアップしましたが、このような簡易構成のRAGは今や古いRAGと言われています。最近のRAGは、検索結果をチェックしたり、検索対象を増やしたり、検索するか否か判断したりと、何かしらの工夫が施されたものが多いです。もちろん、アレコレ機能を追加すれば精度は上がりますが、コストは増大し、処理速度は低下します。それでもRAGは現状、同様の他の技術と比べて、LLMの性能をコスパ良く向上してくれる可能性が高いです。ただし、他と比べてコスパが良いと言っても運用コストは割高ですし、良いと聞いて妄信的に採用するのは危険です。
システム設計を軸に考える場合、LLM導入の目的と照らし合わせてみてください。そこまでして精度を高める必要はありますか?どのくらい精度を高める必要がありますか?そもそもLLMを使う必要はありますか?例えば、レコメンド機能や人のチェックが前提となる箇所には過度な精度は必要ないはずです。既存の技術で代用できる可能性さえもあります。
コストを軸に考える場合、LLMの導入を検討している業務のコストを業務フローに沿って各プロセス別に算出してみてください。LLMで置き換えようとしているプロセスではどのくらいコストがかかっていますか?LLMで置き換えた場合の運用コストはどのくらいですか?RAGで性能UPさせた場合のコストはどのくらいですか?これらを意識するだけで、ROIを意識した導入が可能になります。
さて、言い出すとキリがないのでこのあたりで終わりたいと思いますが、当記事がLLMやRAGと仲良くなる切っ掛けになれたら嬉しく思います。

執筆者紹介





