生成AIについては知識として理解はできているし、凄いのも分かる。だけれども実際の業務や分析をするのにどう役立つのか実感が湧かず、なんか腑に落ちない。そんなモヤっとした気持ちの人に向けて、生成AIを用いた分析の一例をお伝えします。


徐々に疑念が深まりつつある
生成AIを使って分析や業務の効率化!と喧伝され続けているものの、メール文面のベースを作ってくれる。議事録をまとめてくれる。いい感じの画像を作ってくれる。等々、ずっと同じ話題が繰り返されています。その一方で、生成AIを使うことで高度な分析ができる!やら、DXだ!と具体性のない話題も過剰供給され続けていて、実はポジショントークでしかなくて、現実はあまり変わらないんじゃないかって疑念が徐々に深まりつつある人は少なくないと思います。
この記事はそんな疑念を持つ人が、生成AIのポテンシャルをもう一度信じてもいいかな、と前向きに捉えられるようになって貰いたく執筆しています。


小難しいことをしているような感覚
そこで、今回は生成AIを活用した分析をテーマについてお話ししようと思います。
分析と言ってしまうと小難しいことをしているような感覚になりますし、生成AI を使った分析となると一層その感が強くなります。そこで分析を、1.電子化 して 2.構造化 して 3.分析 するというステップに分解します。これらのステップのどこで生成AIが使えそうかという問題に置き換えることで扱いやすくなります。逆に言うと、生成AIが最終成果物を出力することを期待しないと言い換えることもできるでしょう。
電子化やら構造化をはじめとして、話の流れで聞き馴染みのない専門用語が出てくると思います。が、これらは手段の話に過ぎません。必要になった時に、詳しそうな人や生成AIに質問をしてみればいいと思います。
では、次の章から分解したステップごとにどうしていくのかを見ていきましょう。
コンピューターの利用が前提の現代において電子化は必須です
まずは電子化についてです。コンピューターの利用が前提の現代において電子化は必須です。電子化は後続のステップに影響を与えるため重要なのですが、データ入力作業は時間がかかるわりに非常に地味な作業です。また、例えば画像データであったり音声データのように、単に電子化しただけでは使い勝手がよくありません。そこで、テキストデータへの文字起こしや要約をする必要も出てきます。これも単調で地味な作業の割に時間がかかります。ですが、今はChatGPTやGeminiのようなマルチモーダルAIを使って、テキストデータや音声データや画像データ等々を電子化したり要約することで、省力化することが可能です。逆に言うと、これらの元となるデータがないと何もできません。なので、コンタクトセンターに蓄積されたデータは宝の山と言っても過言ではありません。
今回のケーススタディでは、こんな事例でも大丈夫なんだという実感を持ってほしかったため、三国志(原文)を利用します。全文を使ってもよかったのですが、今回はサンプルを群雄に絞っています。
では、作業に移っていきましょう。いきなりですが、翻訳をすっ飛ばして漢文の三国志を日本語に要約します。愚直に翻訳してしまうとトークン数が足りなくなってしまうという現実的な問題もあるのですが、生成AIの気軽さはこういう所で特に感じられます。
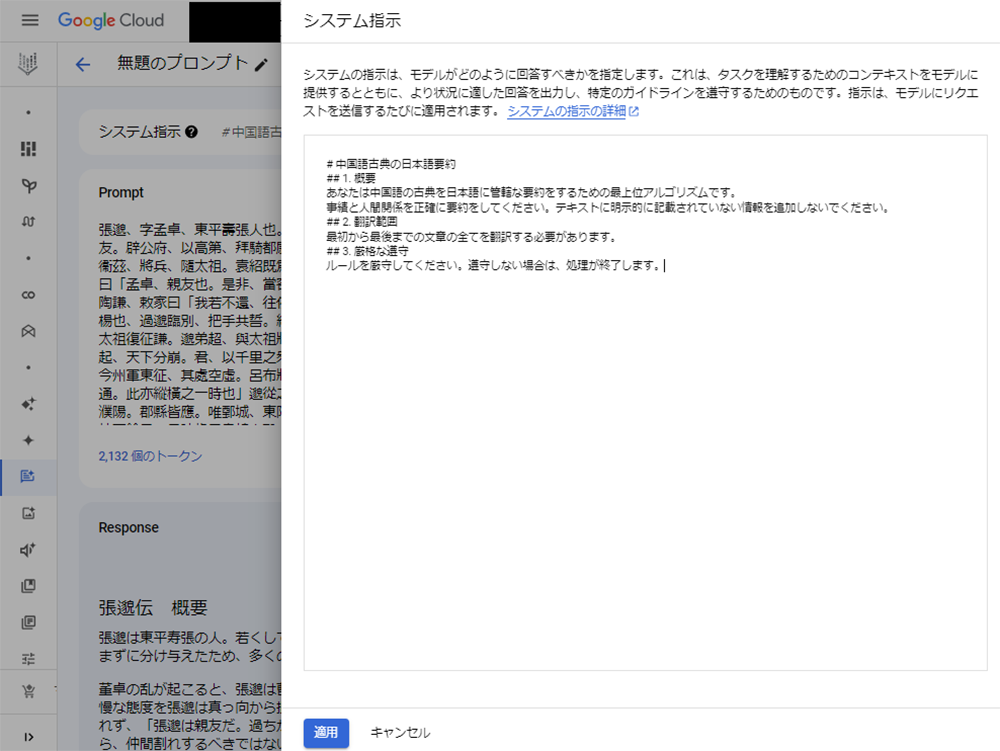
プロンプトを人に見せるのは自分の部屋を見せるみたいでちょっと恥ずかしいですね。閑話休題、今回利用した生成AIは Gemini-1.5-pro です。こだわりのある人達に怒られてしまいそうですが、最先端モデルで比較すると生成AIの性能自体は大して変わりません。そこで、注目したのが先述したトークン数です。最大で200万トークンという膨大な入力トークンもそうですが、8,192という他モデルの倍の出力トークンが非常に実用的です。出力トークン数が不足すると、プロンプトを工夫して何かしらの情報を削る必要が出てきてしまいます。なので、この出力トークン数は非常に魅力的です。
画像の例ではGoogle Cloud の Vertex AI というサービスから Gemini を呼び出しています。プロ仕様っぽい見た目ですが、システムプロンプトとユーザープロンプトの2つに分割されているだけです。一般的なChat GPTやGeminiのインターフェースから利用する場合は、プロンプトを一緒に入力すれば同じことが可能です。
構造化は聞き馴染みのない単語だと思います
電子化ができたら、次は構造化です。とはいえ、構造化は聞き馴染みのない単語だと思います。この辺りを説明しだすと長くなってしまうので、今回は「構造化とは、ある情報を人間やコンピュータが特定の目的のために利用しやすいデータに変換すること」とします。例を挙げるとすると、土地と住所の関係のようなものというとイメージしやすいかもしれません。日本海と信濃川の間にあるチャーザー村のような叙述的な情報は頭に残りやすい反面、正確性に欠けますし、どこに誰が住んでいるのかを網羅的に管理するという目的にもあまり適していません。そこで、住所という形に土地という情報を変換することで管理しやすくしています。
さて、構造化にはよく使うパターンが2つあります。エクセルのような "表形式の構造" とシステムを表す "ネットワーク構造" の2つです。先ほどの住所も "表形式の構造" ですね。都道府県 ⊂ 市区町村 ⊂ 町丁目字のように並べてみると、システマチックに網羅できているのが分かると思います。コンタクトセンターにおいても、いつ、誰から、何について、どんな連絡があったのかというような内容の項目に分類して蓄積していくと思いますし、仕事をするうえで非常に身近な構造だと思います。
対して "ネットワーク構造" は、要素と要素間のつながりに着目した構造です。一番身近な例の一つに人物相関図があります。人物相関図は、要素(=人)と要素間のつながり(=夫婦、親子、知己、強敵(とも)...)で構成されていますね。例はWikipediaのエリザベス1世から生成した相関図の習作です。
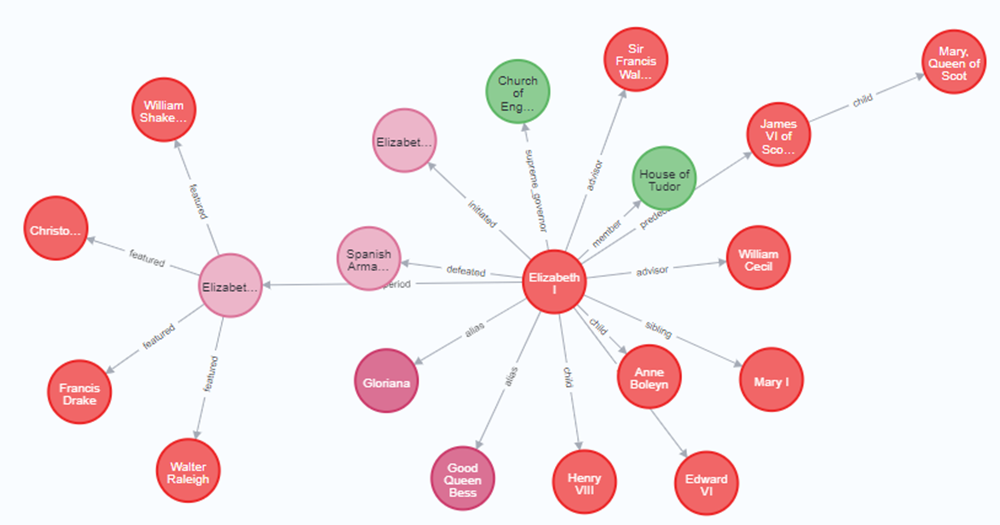
ネットワーク構造は ノード と エッジ の2つの要素で構成されています。ノードは丸で表現されています。ノードとノードを繋いで関係性を表す線がエッジです。
下手な鉄砲も数撃ちゃ当たる
表形式の構造化は普段の業務で接する機会も多く、今回のテーマとしても有用な気もしないこともありません。実際、Embeddingを利用したRAGのように、人口に膾炙した手法も多くあります。ただ、そうすると、ケーススタディが『三国志博士AIの作り方』という毒にも薬にもならない内容となってしまいます。それは主題から外れてしまいますので、今回はネットワーク構造を使ってみようと思います。
今回は三国志のネットワーク構造を、Neo4jというグラフデータベース上に構造化します。グラフとはネットワーク構造の別名程度に思って貰えれば大丈夫なので、ネットワーク構造専用のデータベースとも言えますね。ちなみに、このNeo4jはナレッジグラフの構築にも利用できます。更にそのナレッジグラフを組み込んだGraphRAGという非常に強力な生成AIシステムも構築ができるのですが、ここで紹介するには余白が狭すぎるので、別の機会にご紹介できればと思います。
前置きが長くなってしまいましたが、構造化を進めていきましょう。先ほど翻訳した三国志の要約をNeo4jが読み込めるようCypherという専用のプログラムに変換します。小難しそうな雰囲気を感じるかもしれませんが、中国語古典から日本語に翻訳したように、日本語からCypherに翻訳すると捉え直してもらえれば、そんなに大したことをしていない感覚を持てるかと思います。
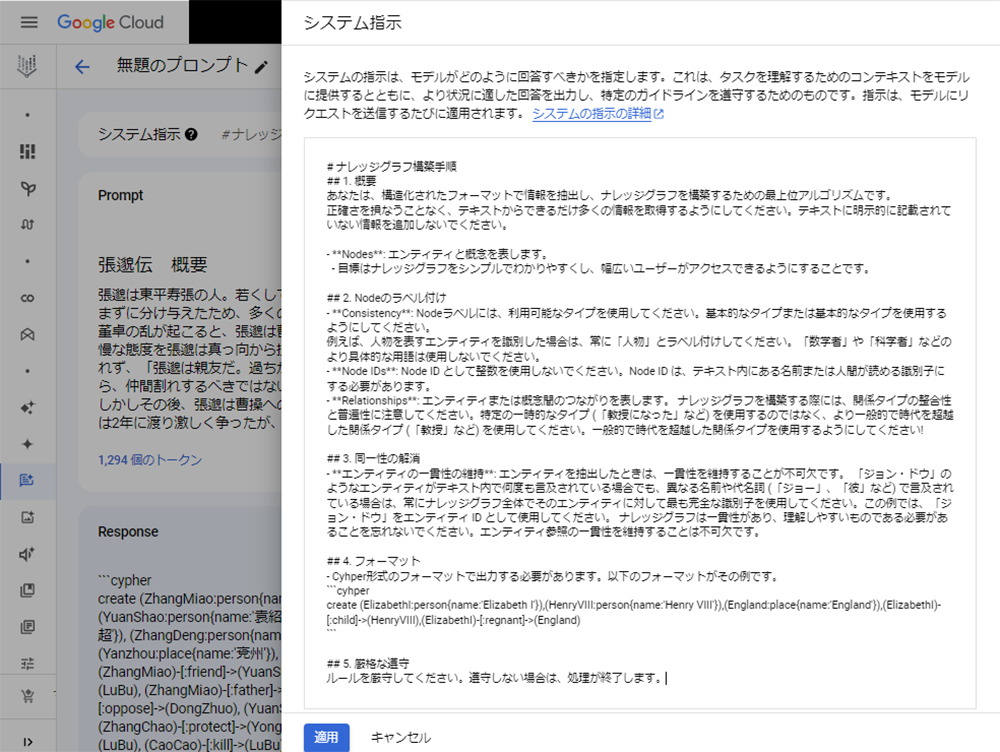
以下の画像が作成したCypherをNeo4jで実行させた結果の一部です。
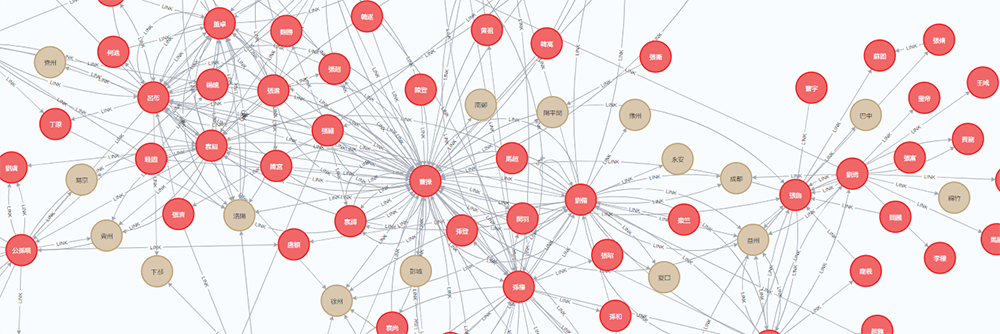
今回のお題である三国志はノードに人物と土地を、エッジにはどういう関係があるかを指定しています。ただ、実際に構造化するにあたっては、ノードに何を定義するかを模索するのは非常に難しい問題です。ここで生成AIを利用する強力なメリットが発生します。生成AIによる省力化は、試行錯誤の回数を大幅に増やすことが可能になります。これにより、正解に対して漸近的なアプローチが可能になります。下手な鉄砲も数撃ちゃ当たる作戦とも言えますね。ですが、この高速な試行錯誤の繰り返しこそ、生成AI利用の真骨頂と言えるでしょう。
これ以上分析を進めると趣味の記事になってしまいそう
せっかくグラフ化したので、Neo4jに標準で搭載されている分析アルゴリズムを使って分析してみます。コミュニティ検出や類似度など面白そうなアルゴリズムがいくつかあるのですが、今回は中心性というアルゴリズムを使ってみます。中心性は、ネットワークを構成する各ノードがそのネットワークの中でどれくらい重要であるかを数値で表すことができます。中心性を求めるアルゴリズムは色々とあるのですが、今回は調和中心性アルゴリズムという、とりあえずコレを使っておけって言う無難なアルゴリズムを使います。
| rank | person | score |
| 1 | "曹操" | 0.4041504539559014 |
| 2 | "曹丕" | 0.3645265888456551 |
| 3 | "孫権" | 0.3488326848249027 |
| 4 | "袁術" | 0.3326848249027237 |
| 5 | "袁紹" | 0.3212062256809337 |
非常に、それっぽいランキングになりましたね。これ以上分析を進めると趣味の記事になってしまいそうなので、これにて分析は終了です。
ケーススタディは三国志でしたが、コンタクトセンターに集められたお客様の声をネットワーク構造(ナレッジグラフ)に構造化することができれば、例えばこの中心性アルゴリズムを使うことで、お客様の悩みやニーズが可視化されるかもしれませんし、類似度アルゴリズムを適用することで、何かのパターンが見つかることもあるかもしれません。例え新しい発見がなくとも、経験則の裏付けが得られるかもしれません。機械的な分析な分、いつもと違った景色が見える可能性があるかもしれない可能性にちょっとワクワクしますね。
まとめに代えて ―仕事の文脈は現場を知る人たちから生まれると思います
生成AIの力を借りて電子化と構造化のステップに分けることで、例え2000年近く前の中国語古典であっても分析をすることができました。それはつまり、専門性やプログラミング等のスキルがなくても、個人が可能になる仕事の範囲が広がると言い換えることができるでしょう。
最近の生成AIの華々しい登場に目がくらんでしまったり、DXのようなバズワードに飲み込まれてしまったり、自分の立っている場所が分からなくなる瞬間があるかもしれません。しかし、仕事の文脈は現場を知る人たちから生まれると思います。つまり、新しいテクノロジーを現場に取り込むのに必要となるのも現場の力になるはずです。このコラムを通して、自分たちの仕事をデザインしていくことの再発見と、そのお供としての生成AIが使えるかもしれない可能性を感じ取ってもらえれば幸いです。
執筆者紹介





