Anthropic社から提供されている、Claude 3という大規模言語モデルが注目を集めています。
Anthropic社はOpenAI社の元従業員でChatGPTの開発にも携わった方々が在籍している企業です。
Claudeは人間による強化学習に依存せず、Constitution(憲法)と呼ばれているAIモデルにより出力の信頼性を上げるアプローチがとられたモデルです。本記事では、2024年3月現在の見解に基づく、コンタクトセンター業務での当モデルの有用性について考えます。
※本記事の情報は2024年4月現在の情報です。


Claude 3とは
Claude(クロード)はAntropic社が提供している、日本語にも対応した大規模言語モデルです。
Claude 3は2024/3/5にリリースされた、Haiku/Sonnet/Opusの三つのモデルを指しています。
それぞれ申し込みは必要なものの、AWSはHaikuとSonnet、GCPではすべてのモデルをクラウド基盤上にデプロイして利用できるほか、Antropic社も有償ですべてのモデルを使えるAPIを提供しております。
パラメータ数については非公開ですが、モデルの大きさで並べるとOpus > Sonnet > Haikuの順になります。
Opusはラテン語で「芸術作品」、Sonnetは「ソネット」つまり14行詩、Haikuは皆様ご存じの「俳句」が語源で、大きさに準じた名づけがされているようです。
早速ですがそれぞれのモデルを使った際のコストを見てまいりましょう。
表:各モデルごとのAPI利用コスト
| 100万トークンあたりの価格 | ||
|
モデル |
入力 |
出力 |
|
Claude 2 / Claude 2.1 |
$8 |
$24 |
|
Claude 3 Haiku |
$0.25 |
$1.25 |
|
Claude 3 Sonnet |
$3 |
$15 |
|
Claude 3 Opus |
$15 |
$75 |
|
(参考)gpt-4 |
$30 |
$60 |
|
(参考)gpt-3.5-turbo-0125 |
$0.5 |
$1.5 |
出典:
Claude: https://www.anthropic.com/api
GPT: https://openai.com/pricing
特筆すべきこととして、「Claude 3 SonnetはClaude 2よりトークン単価が安い」というものがあります。手元で検証した限りにおいては、Claude 3 SonnetはClaude 2よりも性能が良いのですが、それにも関わらず、費用は半分以下になっています。これはおそらくモデルの圧縮によるものと考えられます。昨年、生成AIのブームに伴い、ビジネスシーンでは「どれだけモデルのパラメータ数が多いか」という話題をよく目にしました。パラメータ数が多ければ多いほど、確かに応答は正確になっていきますが、同時にチューニングのコストが上がっていき、更にランニングコストや応答速度にも問題が起こります。ですので、「モデルのパラメータ数をどう適切に圧縮するか」というのが最近の課題となっていますが、Claude 3は何らかの方法でパラメータの圧縮ができているのかもしれません。
この表の数字だけを見ると、gptと比較した時にもコストメリットがありそうに見えます。ただ、モデルについては「安ければいい」という話ではありません。性能の問題もありますが、加えてモデルごとに出力特性が異なるため、単純比較を行うのが難しいです。ベンチマークなども「何を基準にするのか」によって結果が変わってきてしまいます。本記事ではいったん私たちコンタクトセンターのプロフェッショナルの立場からClaude 3の出力を試し、「コンタクトセンターでのビジネスにClaude 3 は使えそうか」という視点で可能性を探ってまいります。
更に、Claude 3はモデルの性能と比較して速度が速いように見えます。今回コンタクトセンターの模擬データで比較を行いますが、Sonnetで30秒、Haikuでは10秒ほどで応答が返ってきており、出力の精度を考えると非常に高速に見えています。


通話ログを基にした検証
実データを使った検証を一般公開の記事にするのは各種セキュリティの問題があり現状非常に難しいのですが、ベルシステム24はコンタクトセンターのプロフェッショナルでして、「実際のお客様からのお電話に近い通話ログ」を作るのは得意中の得意な分野です。今回の検証に先立って、弊社スタッフがお客様からの通話に見立てた7分程度の音声データを作成しました。次にこの音声データをAmiVoiceを使ってテキスト化してみました。テキスト化されてCSVで出力された内容は以下の通りとなります。
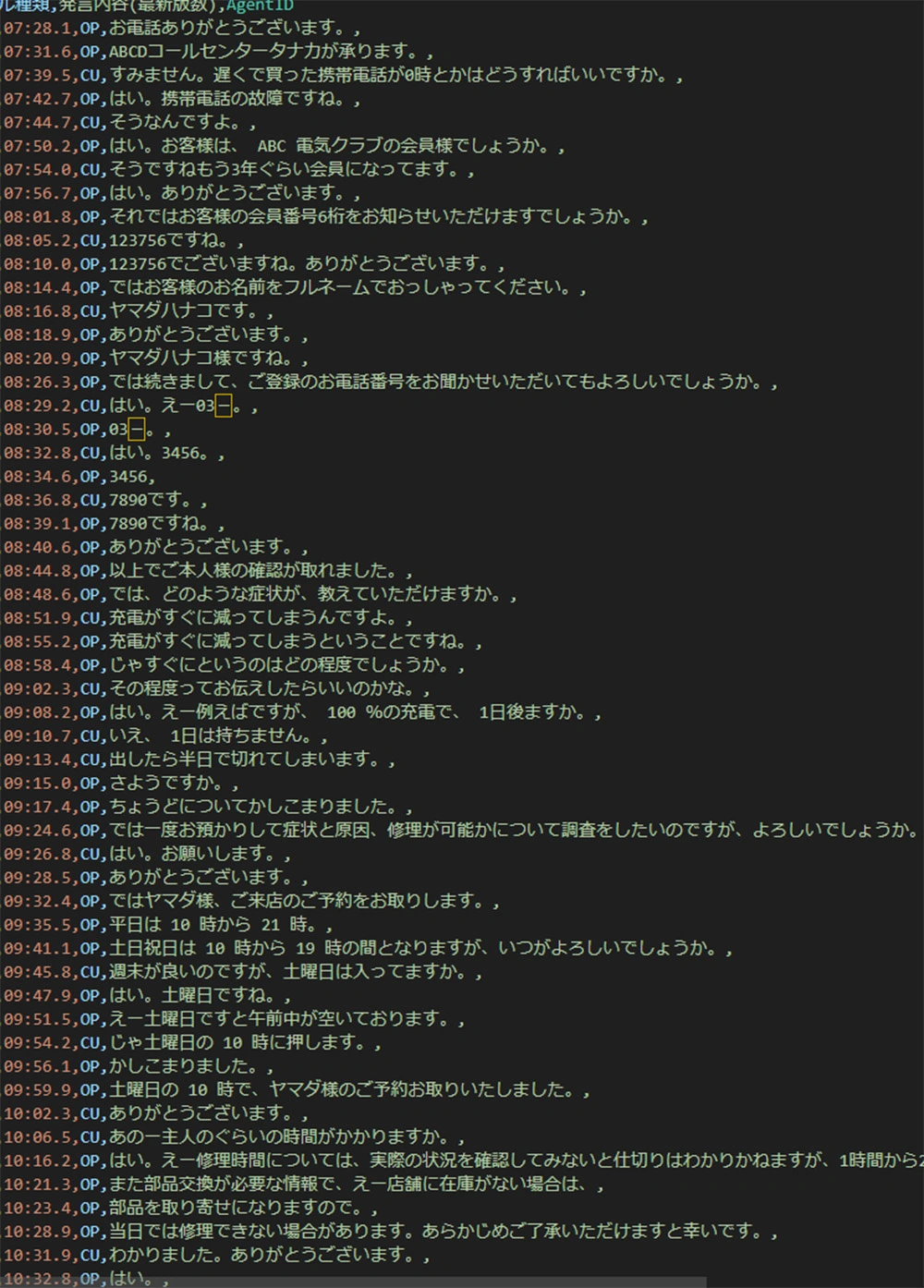
弊社ではAmiVoiceの音声認識精度を上げるためのチューニングもご要望に応じて実施可能ですが、この例ではまだチューニングがされていないため誤認識が多少あります。いったん誤認識されている部分も修正せずに、実データベースでClaude 3の性能を見てみようと思います。
続いて、検証環境の構築方法を簡単に説明します。前提条件は、「LangChainを使えてAWSのコンソールとCLI経由でのアクセスが可能な環境」です。
AWSのコンソールからBedRockにアクセスしてモデルアクセスをリクエストすると、すぐに使えるようになります。
※執筆日現在、Claude3はバージニアとオレゴンのリージョンからしかアクセスできないのでご注意ください。また、会社環境でアクセスする場合、各社のセキュリティの規定に従ってご利用ください。
ここからboto3の認証を通し、langchain_community.chat_models.bedrockを使えるようにすると、検証ができるようになります。
プロンプトはシンプルに
コールセンターのお客様とコミュニケーターとの会話ログを入力する。
要約を箇条書きで出力せよ。
プロンプトについては記載しないこと。
という内容にしてみました。結果は以下の通りです。
Claude 3 Sonnet

Claude 3 Haiku

検証の評価
ログ1件でModelの性能を評価するのはナンセンスではあるのですが、ある程度見えてくるものはあるので定性的にレポートをしてみます。「箇条書きで概要を出す」という使い方をする限り、SonnetもHaikuもどちらも十分に要約ができています。ハルシネーションのような挙動も見受けられず、コストを考えると十分な性能に見えてます。また、音声認識に誤りがあってもある程度は吸収してくれるのもうれしいポイントです。「ちょっと要約をしてみる」というユースケースに限っては、文句のない性能といえます。
反面、このモデルに限ったことではありませんが、専門性の高い話を要約しようとしたり、出力を業務に合わせてコントロールしようとすると一気に難しくなります。今回の事例ではお客様との調整を経て決定した日程の要約はできており、「金曜日に携帯を預けて土曜の午前中に修理したものを受け取る」という出力はしてくれています。これ自体は本当に素晴らしいことなのですが、コンタクトセンターの後処理では通常「何月何日なのか」の明示が必要です。これは音声ログ上にはない情報で、生成AI単体では難しい出力となります。
今回の検証をまとめると、以下のようなところとなります。
- コストパフォーマンスが良い
- 利用も簡単
- 出力性能はコストに対しては十分
- 人間の出力に合わせようとすると生成AI単体では難しい。
ベルシステム24では、生成AIを業務でどう活用するかの企画や検証を日々行っております。今回ご紹介したBedrock上のClaude 3以外にも、Azure Open AIやVertex AIなどを用いた検証も進めております。業務の効率化や、コンタクトセンター業務での後処理の削減などにご興味がある方は当社にぜひご相談ください。
執筆者紹介












