前回(こちら)から引き続き後編をご紹介いたします。
前編では、改善機会手法による課題テーマの選定の方法や、分析要件を定義することの重要性、またデータ準備や前処理のステップについてご紹介いたしました。
後編では、「モデルの選択と学習」により的確なモデルを導入し、「モデルの利活用」では、実務に応用し、具体的な問題解決と、業務や組織の最適化にモデルを活かすための、利活用の考え方を解説します。


モデルの選択
モデルの選択や機械学習は非常に重要なステップです。
まず、解決すべき問題や目標を明確にし、分類、回帰、クラスタリングなど、問題の性質によって適切なアプローチを検討し、利用するデータの特徴や分布を整理し理解します。また、データセットを学習データ、検証データ、テストデータに分割し、適切な評価指標(精度、再現率、F1スコアなど)を定義します。
ベースラインモデル(Baseline Model)の構築
ベースラインモデルとは、プロジェクトの初期段階で使用される簡単なモデルや手法であり、後続の複雑なモデルとの比較のために構築するものです。ベースラインモデルを構築することで、シンプルで周囲のメンバーは理解しやすく、問題に対する基本的な打ち手を講じることができます。また、モデルの改良や複雑化のための基準となり、後続のモデルの開発方針を明確にすることが可能です。
「ロジスティック回帰」
ロジスティック回帰(いくつかの要因(説明変数)から「2値の結果(目的変数)」が起こる確率を説明・予測することができる統計手法です。比較的単純なモデルで理解しやすく、過学習のリスクが少なく、特徴の寄与や重要度を評価しやすい反面、過去のデータが無いなど非線形な問題や複雑なデータ構造には向かないことがあります。
「ランダム・フォレスト」
ランダムフォレスト(Random Forest)は、アンサンブル学習の一種で、複数の決定木からなるモデルです。規模の大きなデータでもスピーディな学習と識別が可能で、特徴量の正規化あるいは標準化が不要な反面、決定木による過学習が出やすく、学習データが少ないと精度が上がらない可能性があります。
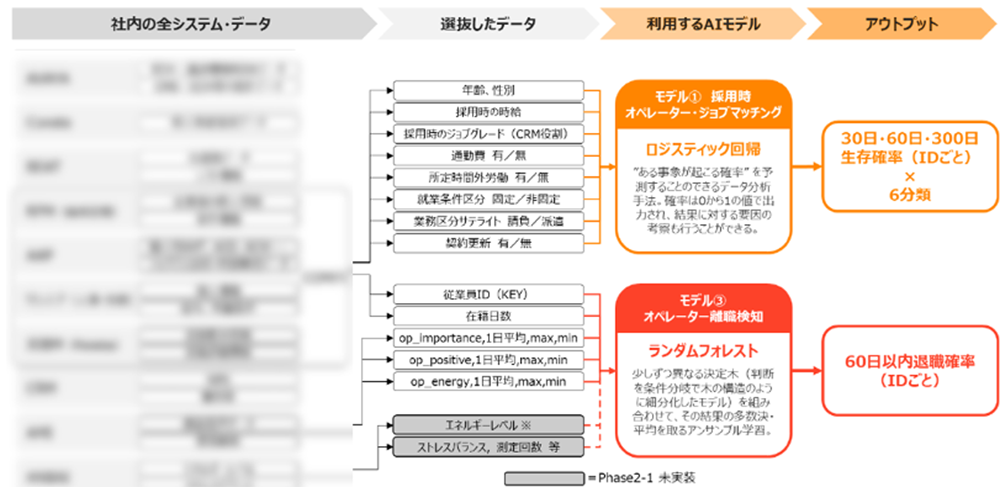


学習のアプローチ
機械学習モデルとは、採用したモデルをデータによって学習させ、未知のデータに対する予測能力を向上させる過程を指します。以下は、モデルの学習における一般的なアプローチです。
1.データの準備
データの前処理、クリーニング、特徴量の選択やエンジニアリングが含まれます。データの品質がモデルの性能に大きな影響を与えるため、慎重に対応する必要があります。
2.データの分割
データを「学習データ」、「検証」、「テストセット」に分割します。モデルの学習には学習データを使用し、検証セットでハイパーパラメータの調整を行います。
3.モデルの構築(初期化)
モデルを選択し、初期パラメータを設定し学習プロセスを開始します。初期化の方法はモデルによって異なりますが、ランダムな初期化が一般的です。
4.損失関数と最適化アルゴリズムの選択
モデルの性能を評価するために損失関数を定義します。損失関数はモデルの予測と実際のターゲットとの誤差を測定します。また最適化アルゴリズムを選択し調整を試みます。
5.モデルのトレーニング
学習データを使用してモデルを学習します。エポック数やミニバッチサイズなどのハイパーパラメータを調整します。
6.モデルの評価
検証セットやテストセットを使用してモデルを評価し、性能を確認します。過学習の防止やハイパーパラメータの微調整が必要かどうかを確認します。
7.モデルのデプロイ
モデルが満足のいく性能を発揮したら、実際の環境にモデルをデプロイします。
8.モニタリングとメンテナンス
モデルがデプロイされた後も、性能のモニタリングや必要に応じたメンテナンスを行います。
これらの手順は一般的なものであり、プロジェクトの性質や目標によって変化することがあります。慎重に検討し、反復的にモデルを改良していくことが重要です。
モデルの利活用
モデルが実際の環境でうまく機能し、ビジネス価値を提供できるようにするために重要なポイントを整理すると、「データ整備とメンテナンス」「利用者への理解促進」「データガバナンスの構築」の3つが挙げられます。
1.データ整備とメンテナンス
適切なデータの入力と出力
モデルが受け入れるデータのフォーマットや範囲を理解し、モデルに適切な形式の入力を提供することが重要です。そのためにデータマネジメントを行う必要があります。
リアルタイム処理への対応
リアルタイムの要件がある場合、モデルの推論処理が高効率で行えるように工夫することが重要です。モデルのサイズやアーキテクチャ、推論エンジンの最適化を行います。
誤差への対応
モデルは常に誤差を含むものです。モデルの出力が誤差を含むことを想定して、その誤差を考慮する工夫が必要です。
監視とメンテナンス
モデルを運用し続けるために、監視、メンテナンス、障害対応のプロセスを確立します。モデルが効果的に稼働し続けることがビジネス上の成功につながります。
2.利用者への理解促進
モデルの利用者に対してAIモデルがどう動いているかをわかりやすく説明し、データの品質やプライバシーに十分注意しなければなりません。また、モデルの限界や誤解を与えないように、利用者のフィードバックを受け入れ、具体的な利用方法や利用のコツなどを運用プロセスに落とし込むことが重要です。
「透明性の確保」
利用者に対して、AIモデルがどのように動作しているか、どのように学習されたかを分かりやすく説明することが重要です。モデルの透明性を確保することで、利用者はモデルの結果を信頼しやすくなります。
「データの品質とプライバシーの確認」
モデルがどのようなデータから学習され、そのデータの品質やプライバシーに対する対策が行われているかを明示することが重要です。ユーザーがデータの取り扱いについて安心感を得ることが重要です。
「エラーと不確実性の伝達」
AIモデルが誤った結果を返す可能性や、特定の条件下での不確実性について説明することが重要です。利用者にモデルの限界や注意点を明確に伝えることで、誤解を防ぐことができます。
「利用者の関与とフィードバックの受け入れ」
モデルが導き出した答えと実態との乖離について正しく認め、あらゆる原因を探るために、利用者とのチームワークを形成し、利用者側の意見などを収集しましょう。これにより、利用者側の立場としてモデルの改善に寄与することができ、モデルがより適切になる可能性があります。
「モデルの適切な利用の指針展開」
利用者に対し、ガイドラインやQAの受付などを設けることで、モデルを効果的かつ安全に利用できるようにサポートすることが重要です。利用者の些細な疑問や不安を決して見逃すことなく、安心して業務を遂行できるよう促すことでモデルの利用頻度の向上につながります。
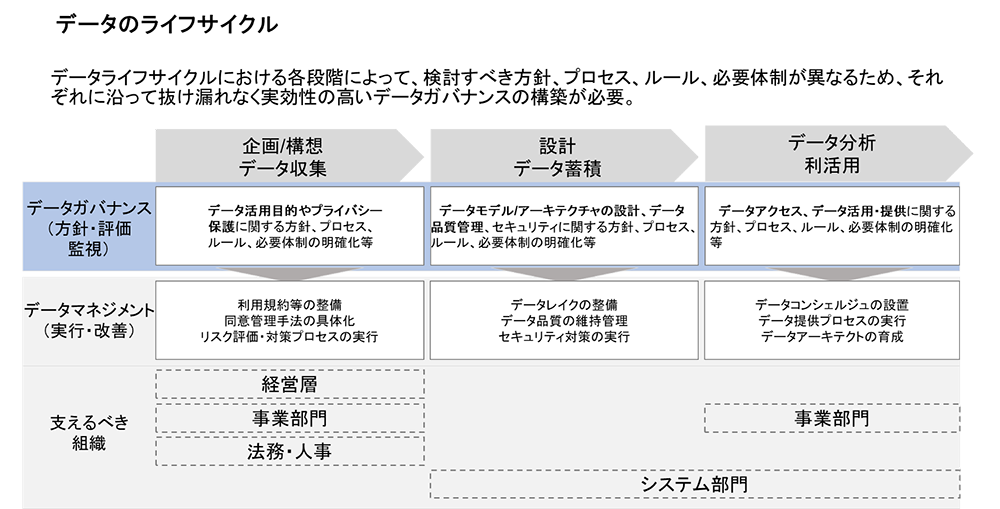
3.データガバナンスの構築
AIモデルを活用する際のデータガバナンスは非常に重要です。データガバナンスは、データの収集、管理、処理、保護に関するルールやポリシーを確立し、実施することを指します。また、企業や組織がAIを導入し、利用する際に信頼性や持続可能性を確保するために欠かせない要素です。適切なデータガバナンスの下でモデルを構築・運用することで、リスクを最小限に抑え、成果を最大化することが可能です。
まとめ
前編では、データ分析プロジェクトの成功の秘訣として、正確な方向性と高品質なデータが不可欠であることを述べました。
後編では、モデルの選択と機械学習の適切なアプローチと、モデルの利活用時における重要なポイントをご紹介してまいりました。
解決すべき問題や目標を明確にし、分類、回帰、クラスタリングなど最適なアプローチで、利用するデータの特徴や分布を整理し理解します。
次に、未知のデータに対する予測能力を向上させるプロセスを定義し、適正な学習によって、でモデルの改良に繋がります。
更に、モデルを活用するために、データの整備とメンテナンスをしっかり行い、利用者への理解促進のためにプライバシーをしっかり確保し、モデルに対する誤解を無くす取り組むことが重要です。また、安全にモデルを利活用できるためのデータガバナンスの構築が前提となります。
これらのことを実現するために、関係者の協力と共、強いリーダーシップが求められます。「コンタクトセンターはデータの宝庫」・・・これを活かすために私たちは日々努力を重ね、データを活用することで未来を切り開くことが出来るのです。
執筆者紹介











